
🆘救命-群晖数据恢复
背景
由于Raid0磁盘损坏,虽然修复了。但是不能持续工作。应该是硬盘出问题了。
解决方案
经过很多波折,终于找到一个解决方案。购买了一个 硬盘克隆机。
https://item.jd.com/100034686006.html
将有问题的硬盘,物理层面克隆。
系统恢复
硬盘是修复了,但是之前的NAS虚拟机没法正常启动了。
解决方案:
重新制作了一个群晖的NAS系统,然后将之前的磁盘全部挂载到这个新系统上。
然后在磁盘管理中,自动识别出来了。
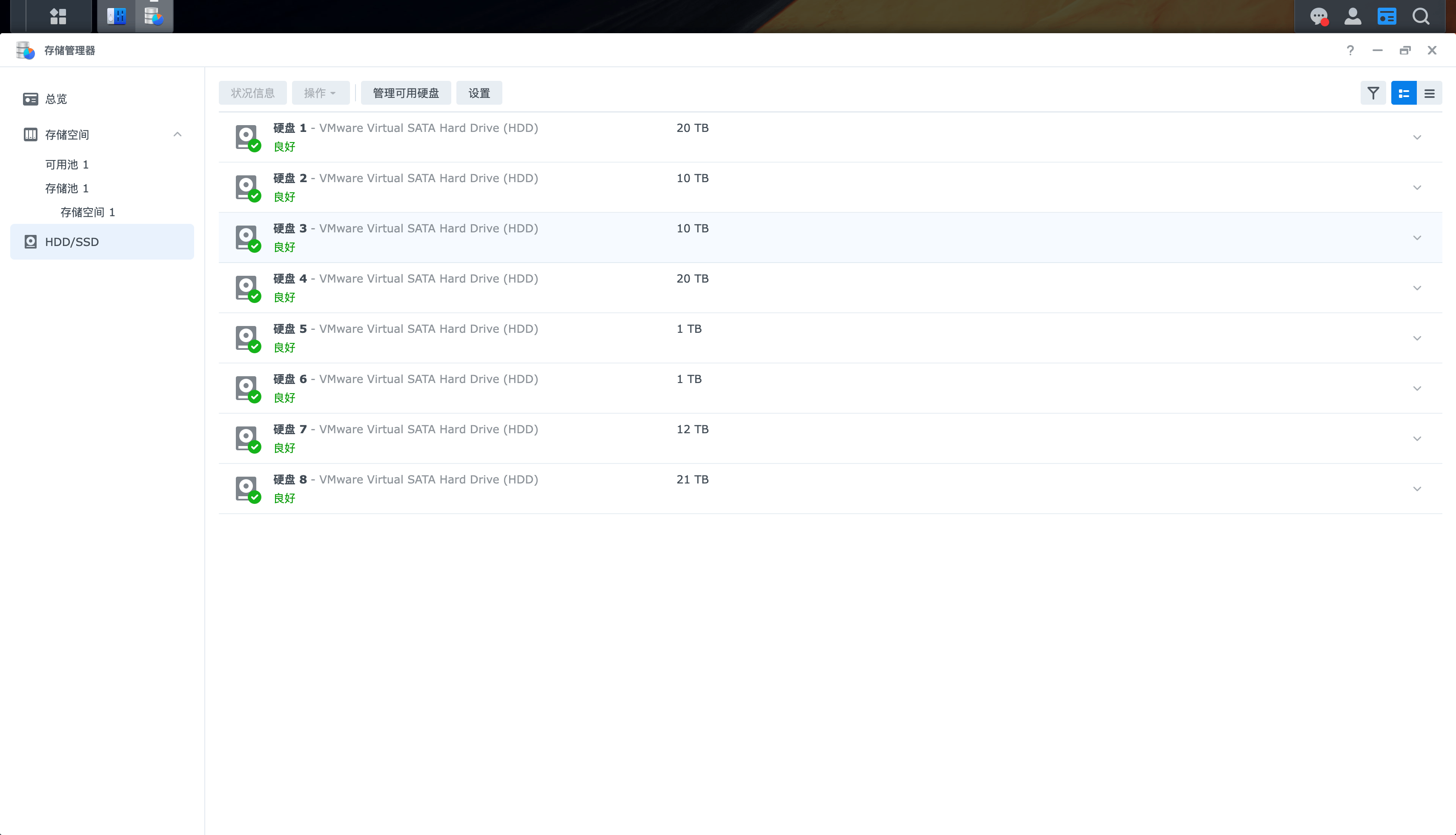
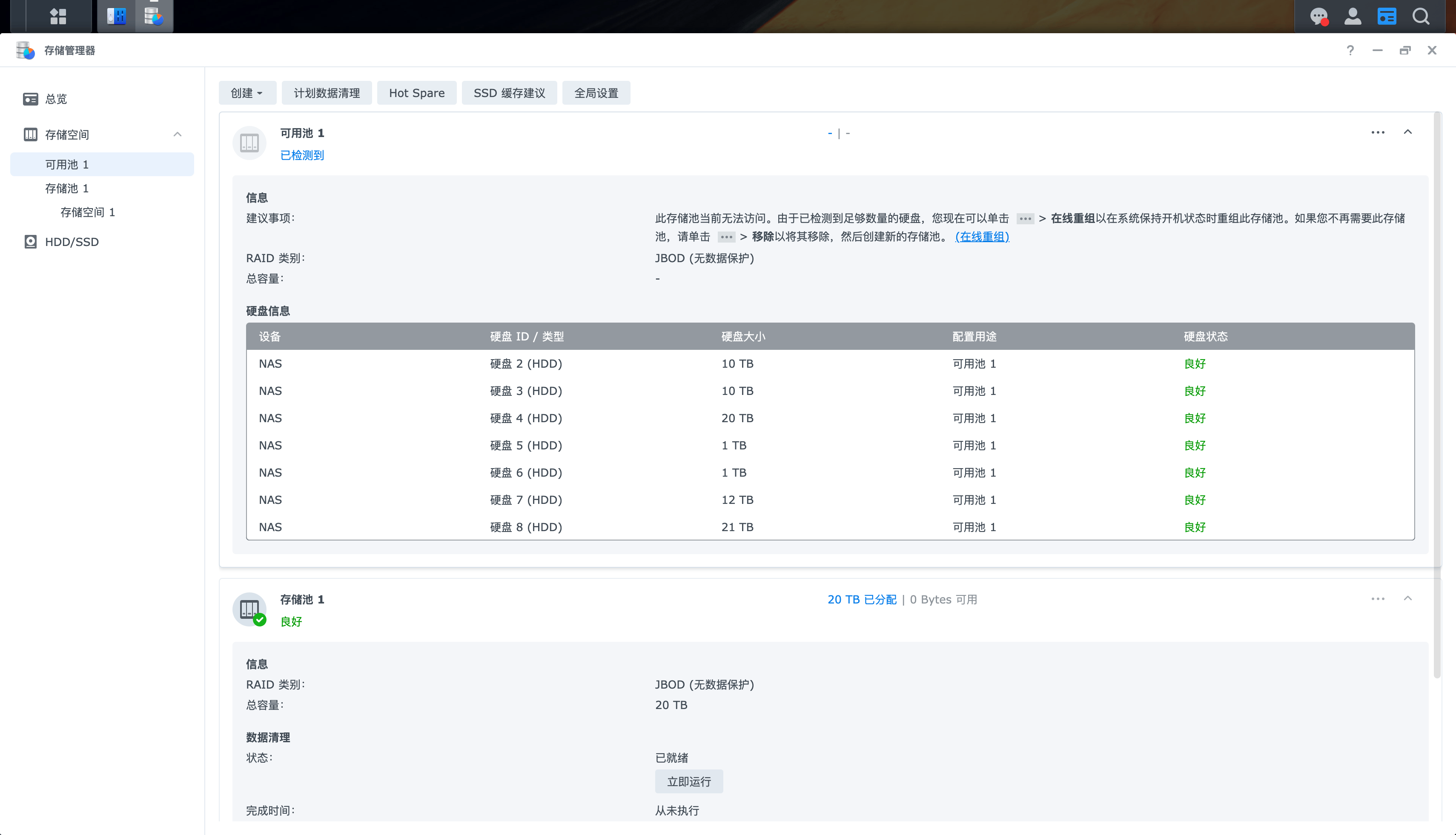
点击这个 在线重组,居然重组成功了。不得不佩服群晖的系统还是做的很不错的。
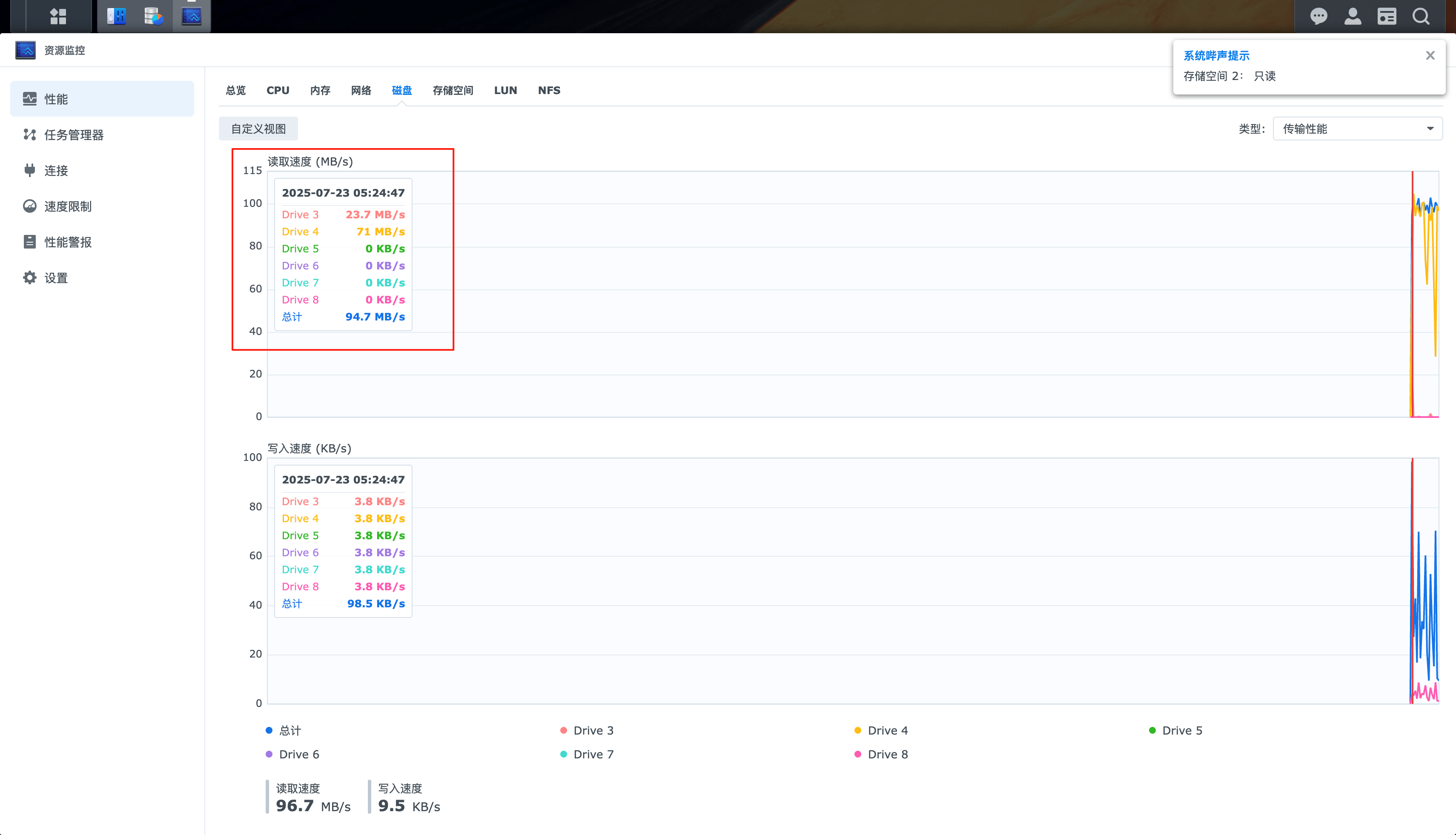
虽然运行一段时间候,出现了存储空间严重的问题。
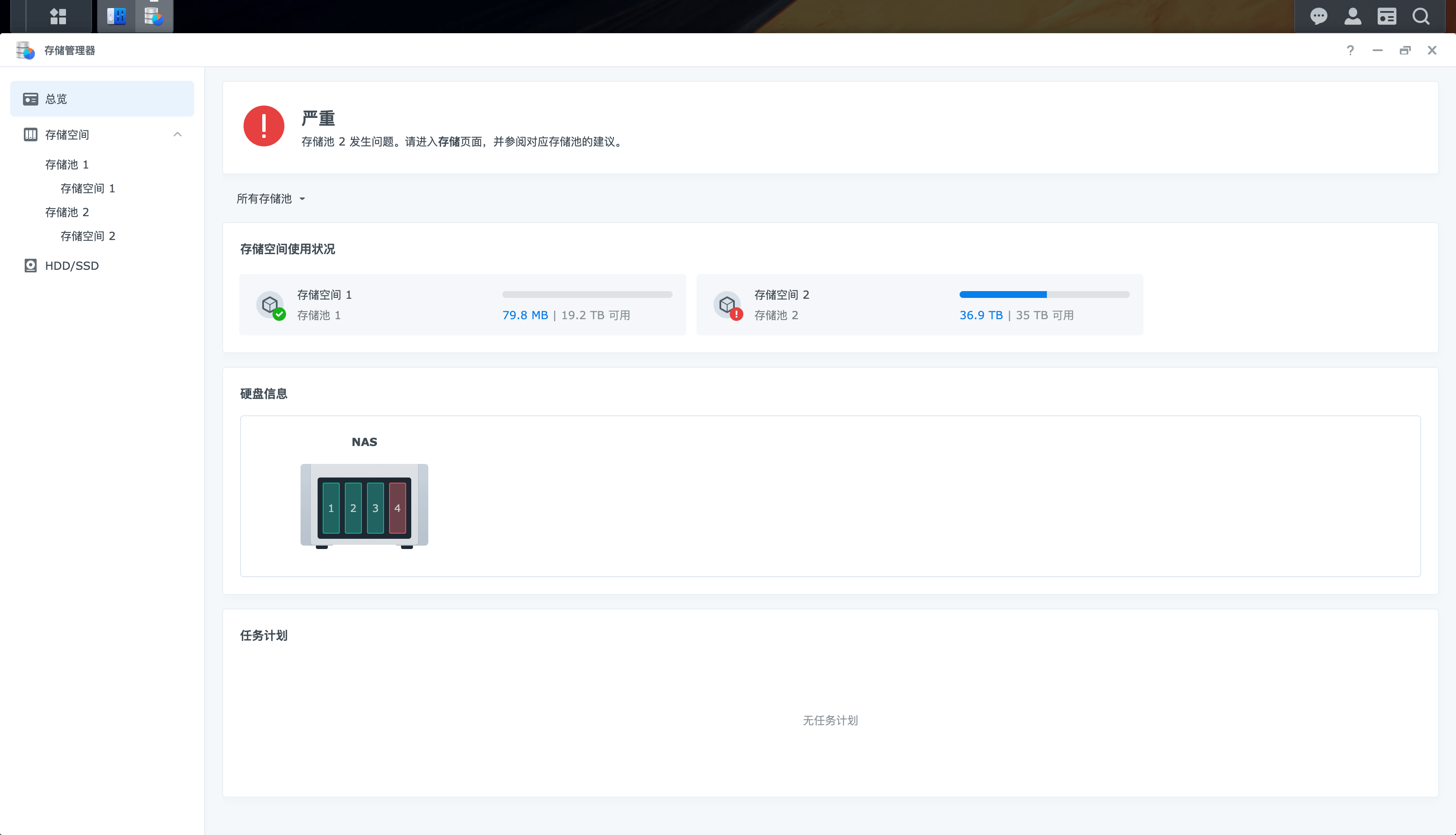
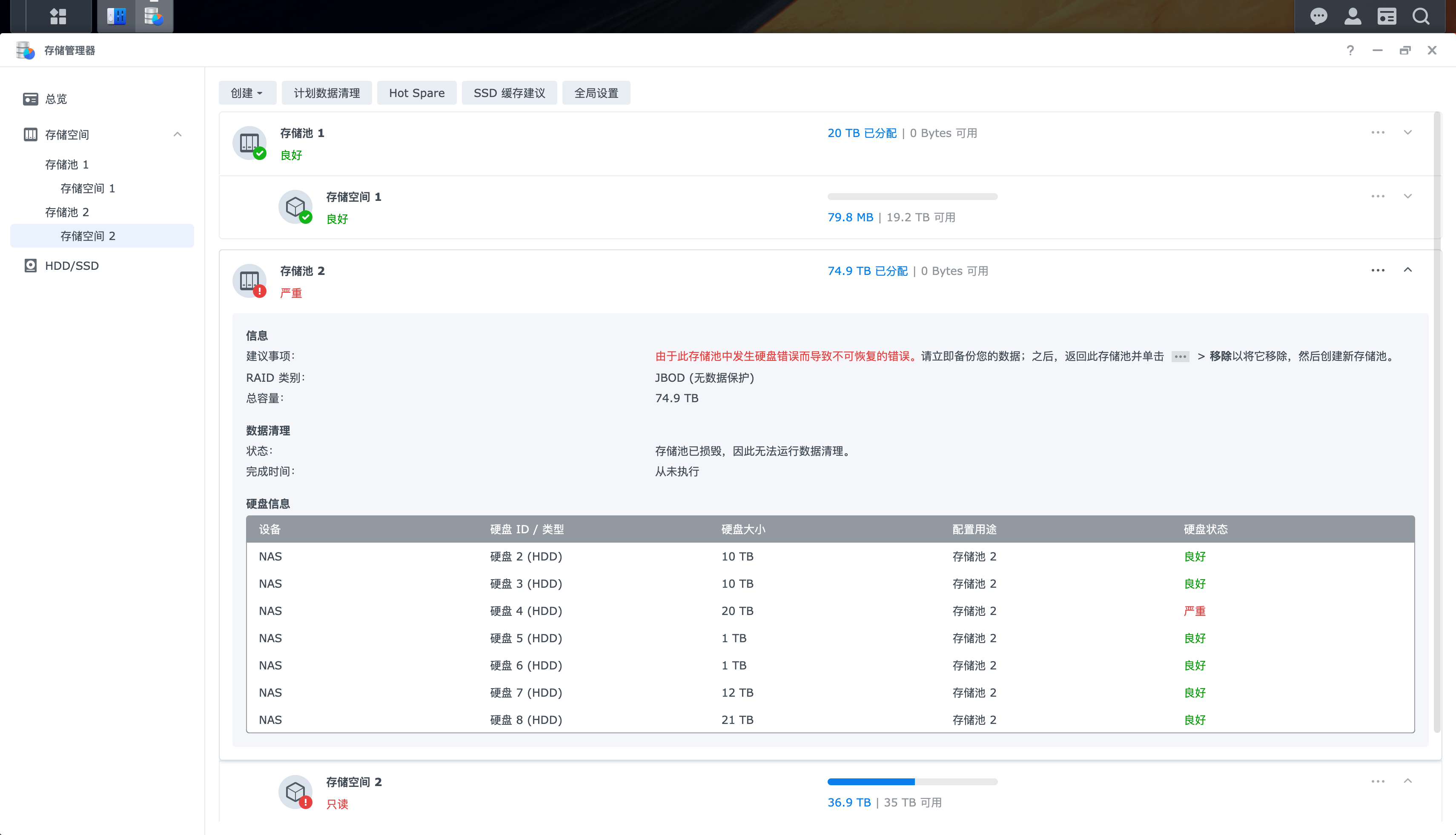
磁盘进入了只读模式。
抢救数据
此时第一要务就是抢救数据
导出数据
在旧系统上,点击更新和还原、系统设置备份、手动导出、导出。
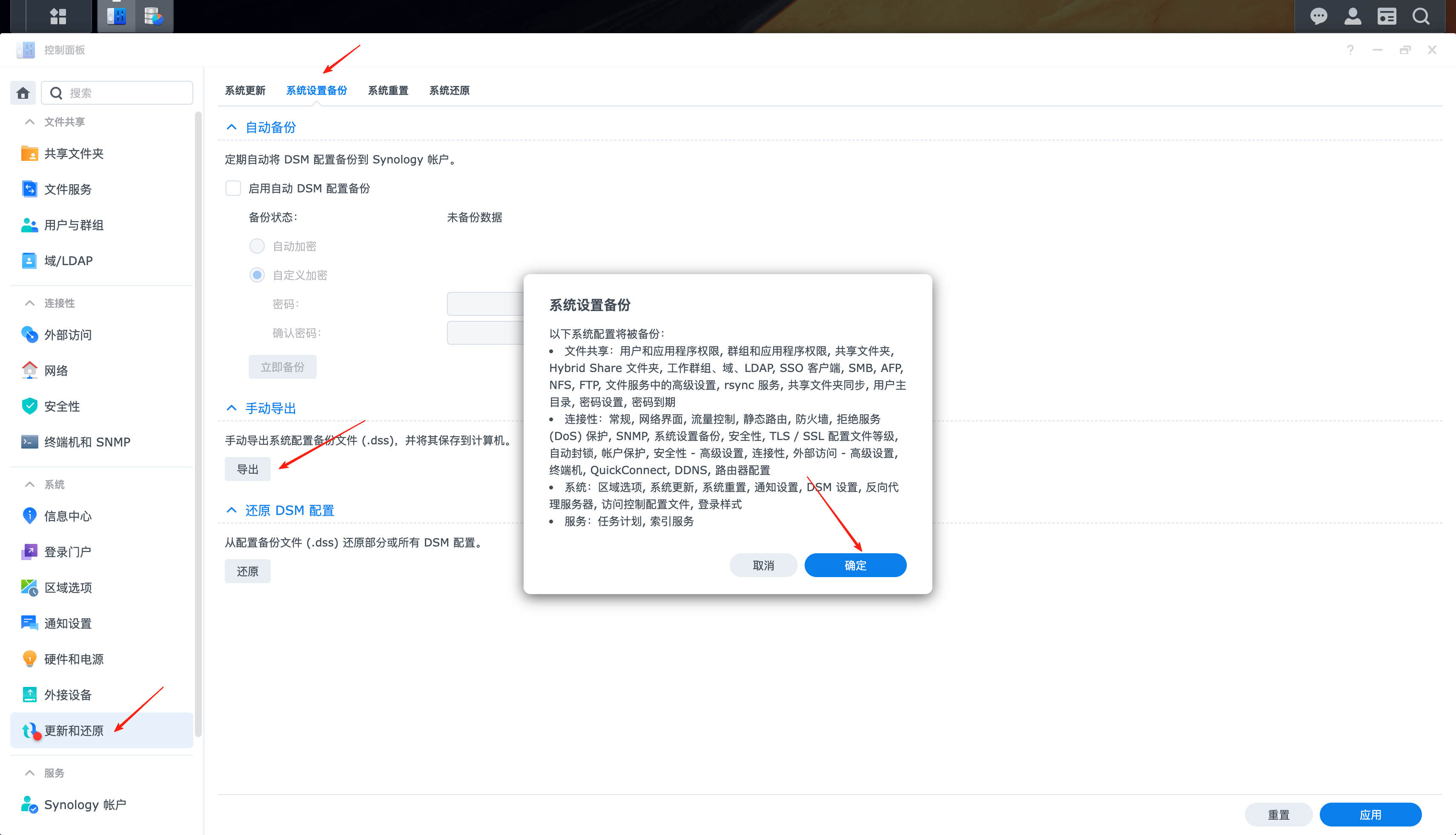
恢复用户
温馨提示
接下来,在新系统上,执行下面的操作。
选择更新和还原、系统设置备份、还原DSM配置、浏览,选择之前导出的备份文件。点击下一步。
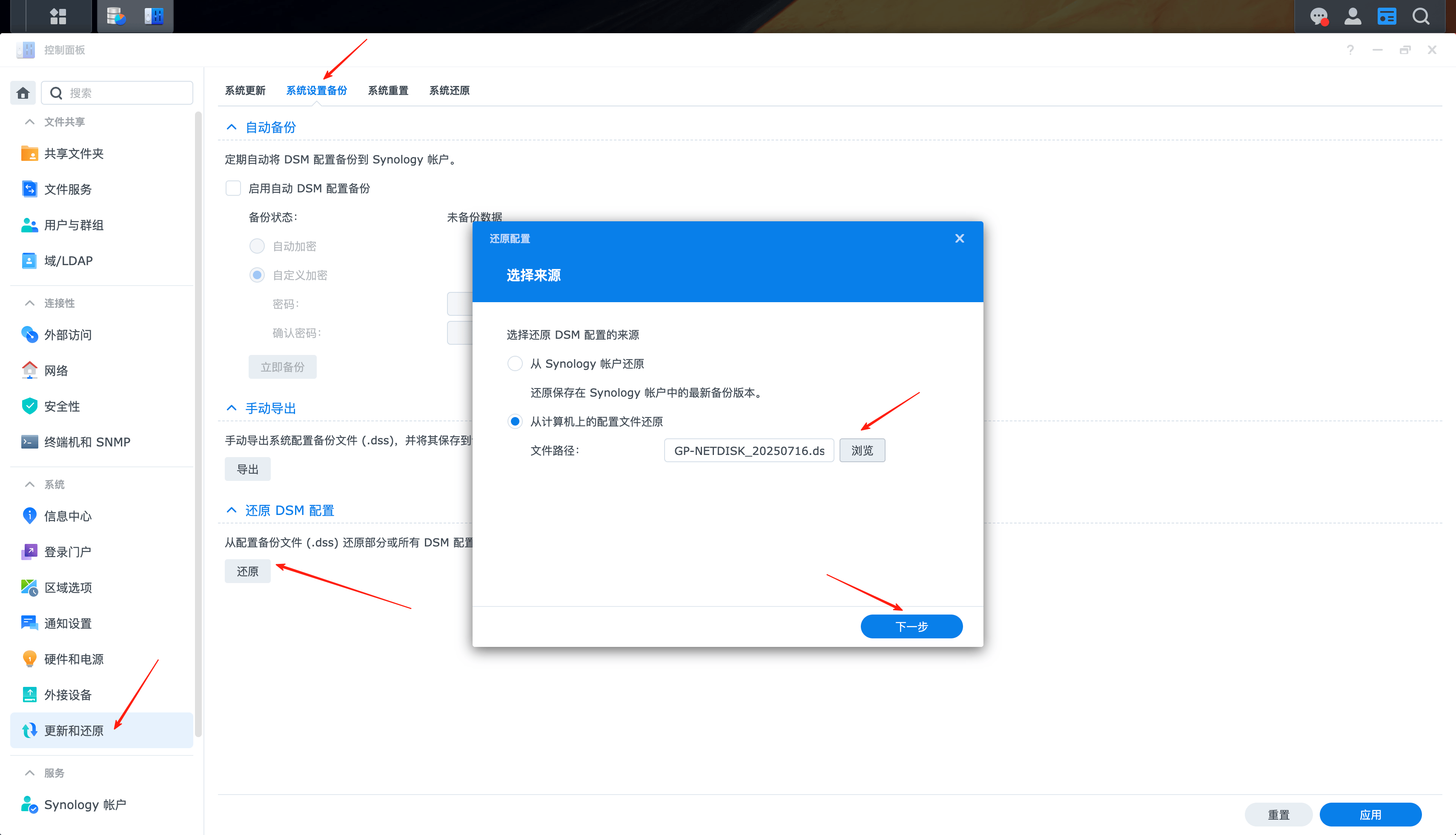
选择需要恢复的数据:
这里我们选择用户、群组、共享文件夹、应用程序和权限、还有登录样式设置。
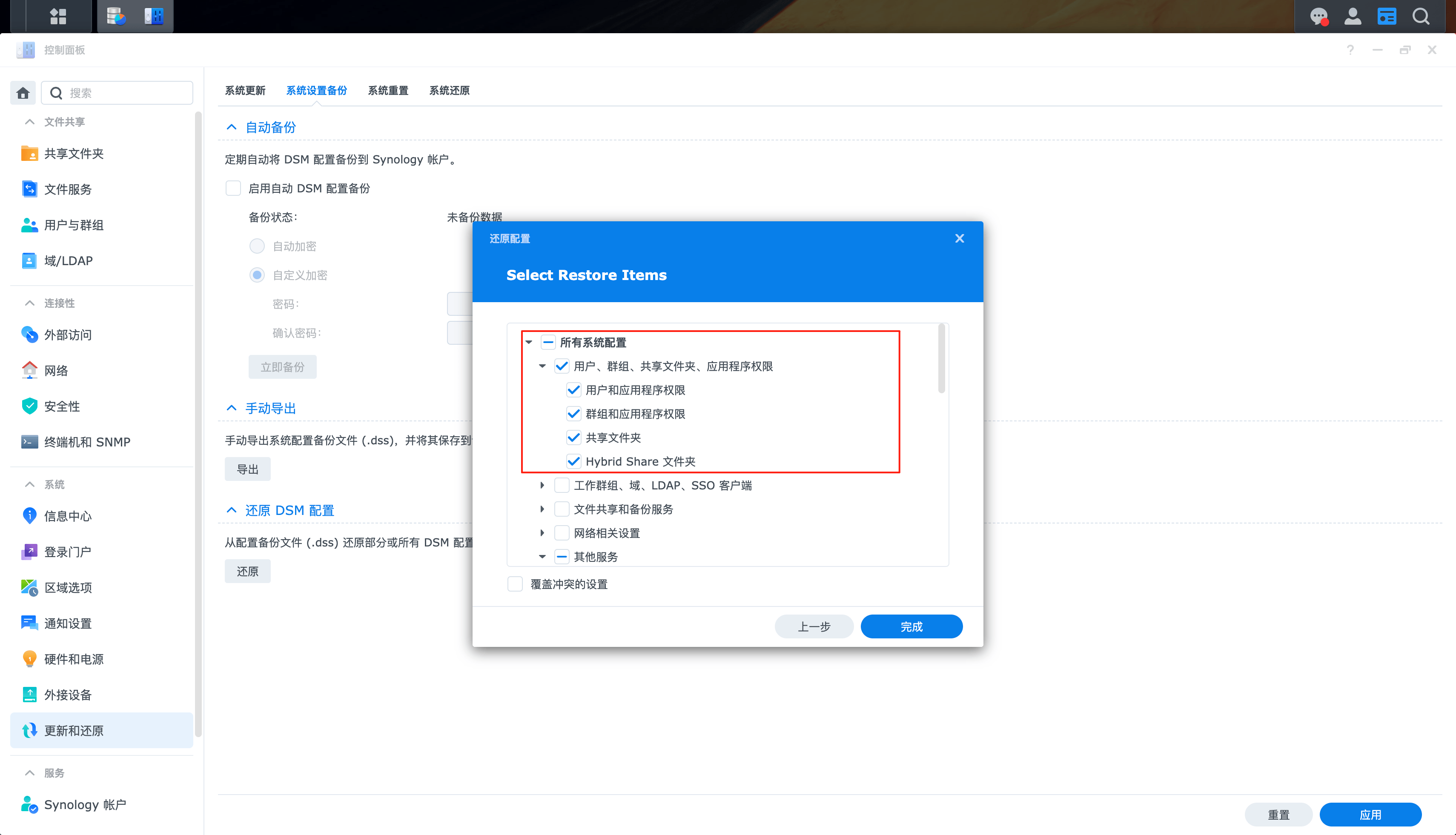
点击完成,等待一段时间候,需要等待一段时间。
恢复数据
此时,共享文件夹已经恢复好了,但是里面没有用户的真实数据。
提示
经过很多种方案尝试,必须通过 rsync,使用scp会导致元数据丢失,例如 权限 丢失、时间等。
我们通过命令行的方式来逐步恢复每个用户的数据
# 因为在线重组后,变成了存储池2,所以我们需要切换到 /volume2
cd /volume2/
# 逐步同步每个用户的个人空间 (支持文件断点续传、只做文件大小判断校验)
rsync -av -e ssh --bwlimit=102400 --progress --block-size=32768 --partial --append --size-only --exclude='#recycle' 番茄的个人空间/* fanqie@192.168.8.87:/volume1/番茄的个人空间/开始稳定传输
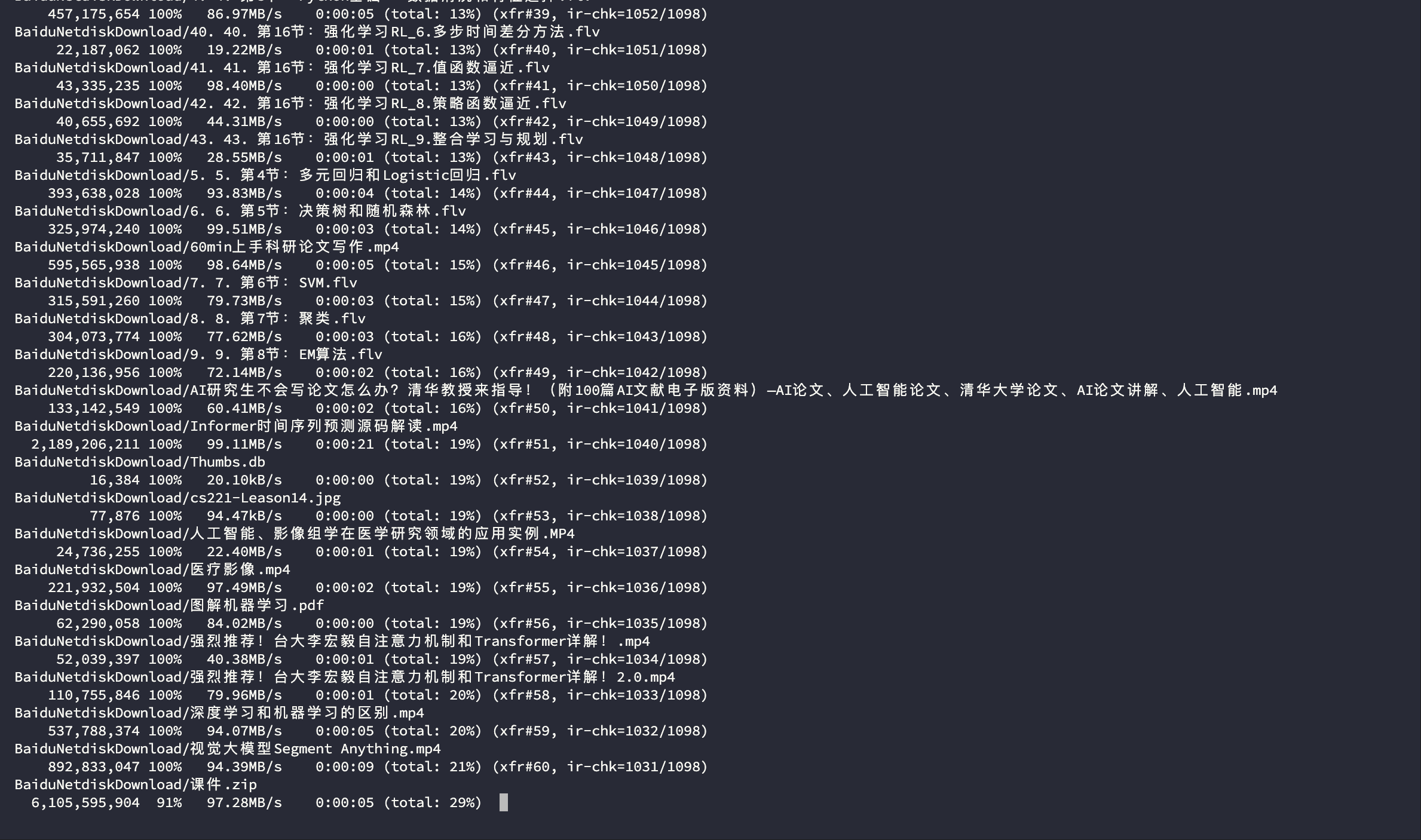
网络稳定在 100M/s:
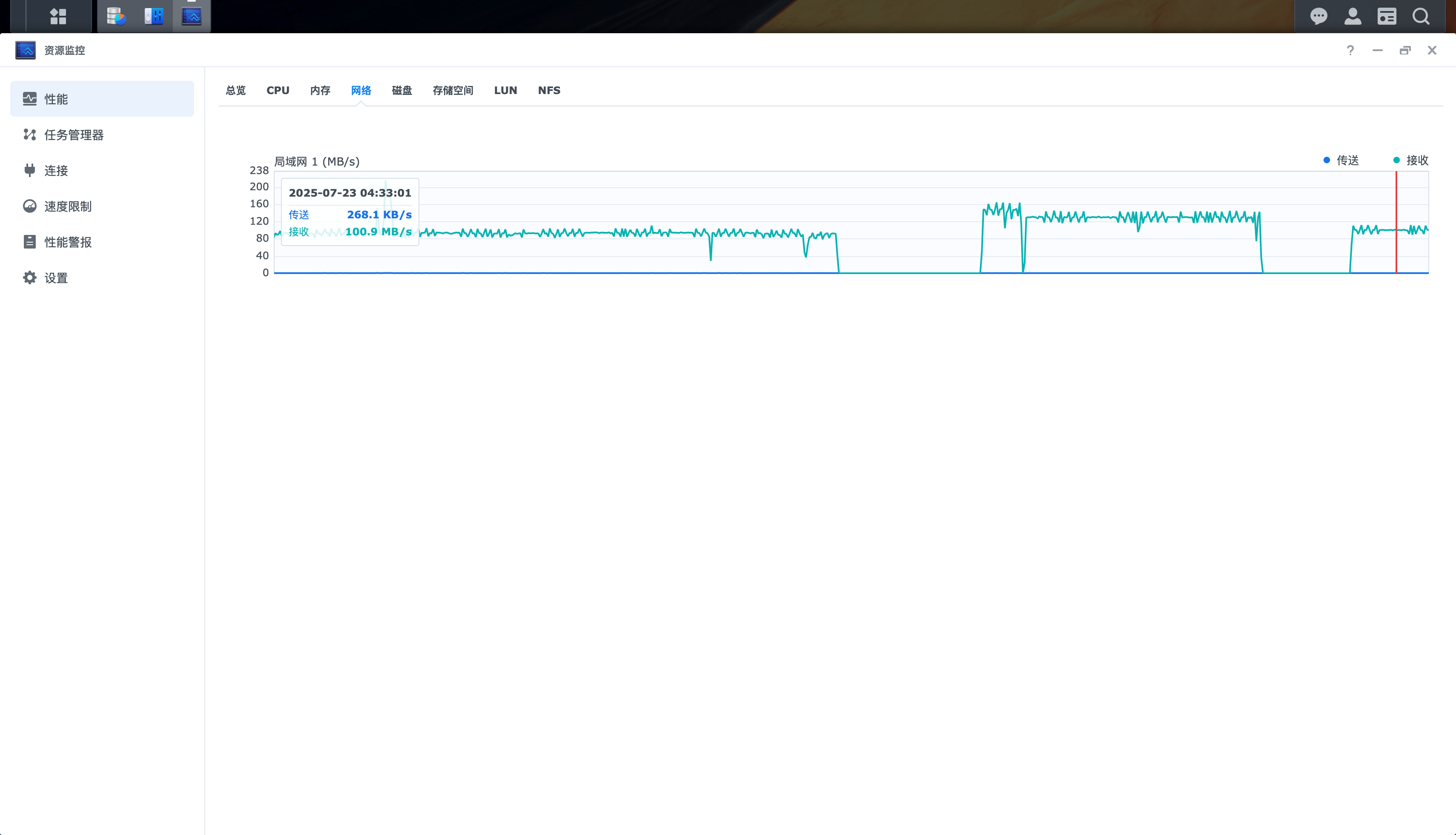
磁盘最高并发在300M:
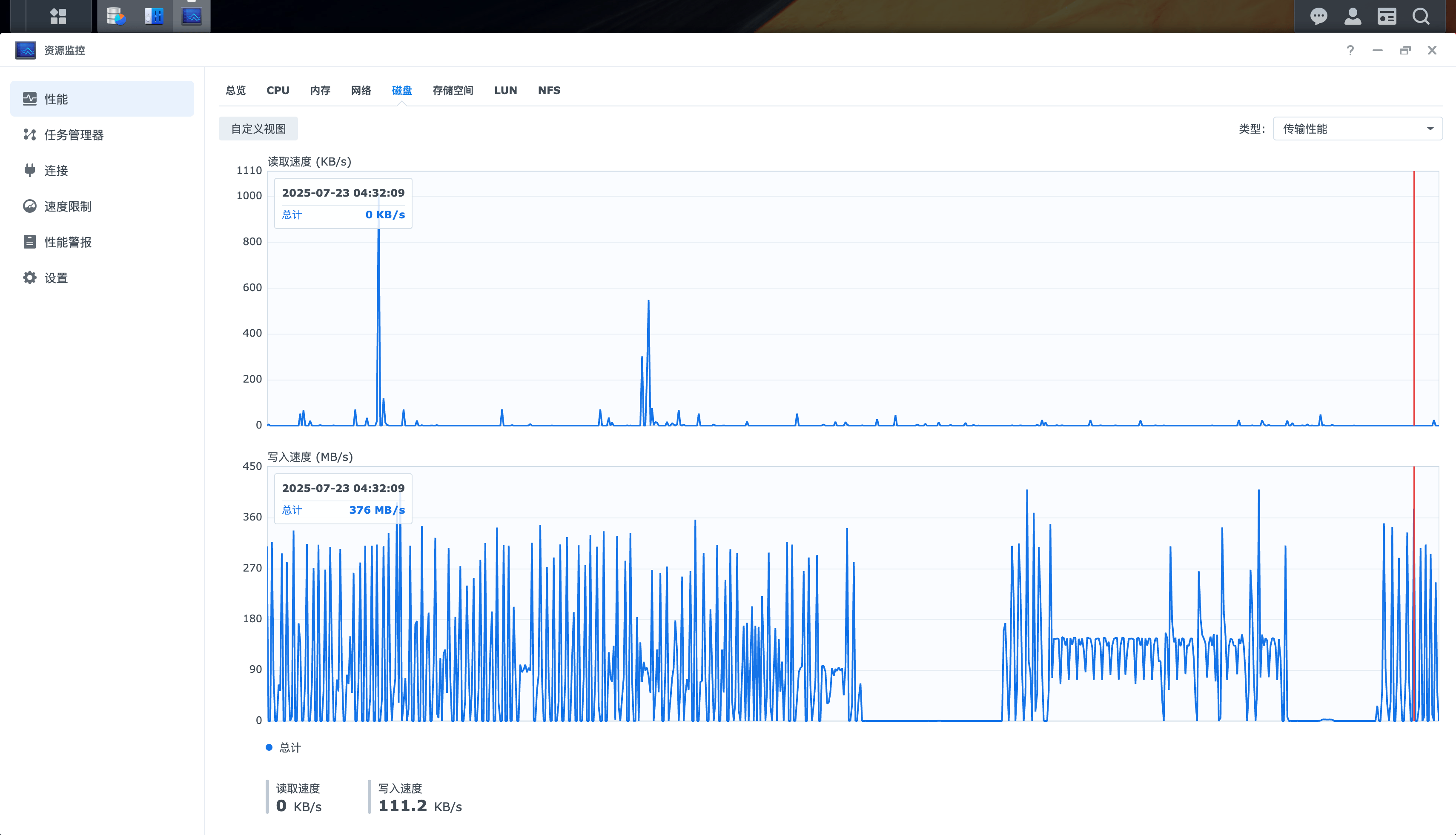
CPU和内存负载都比较小
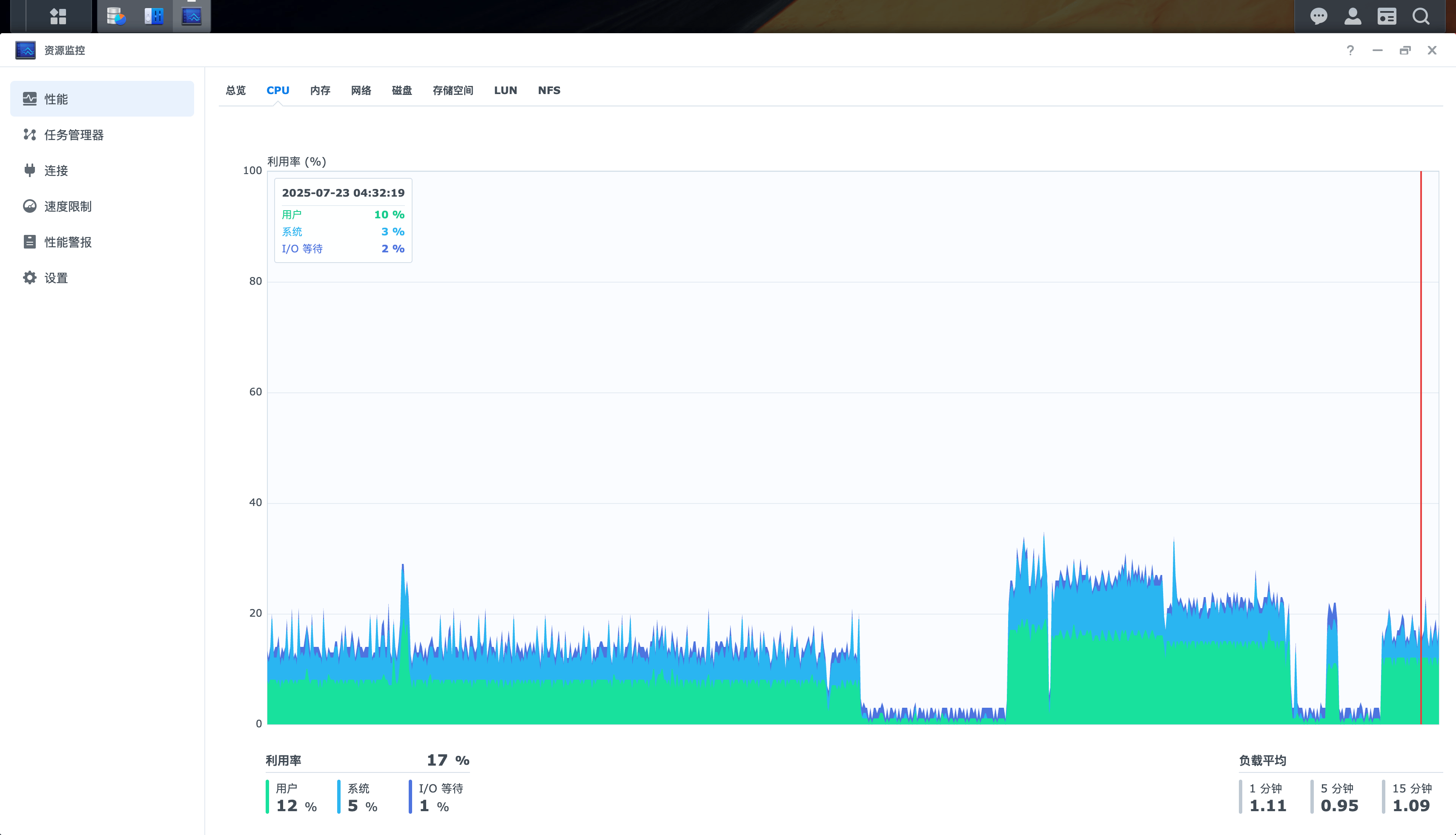
内存负载
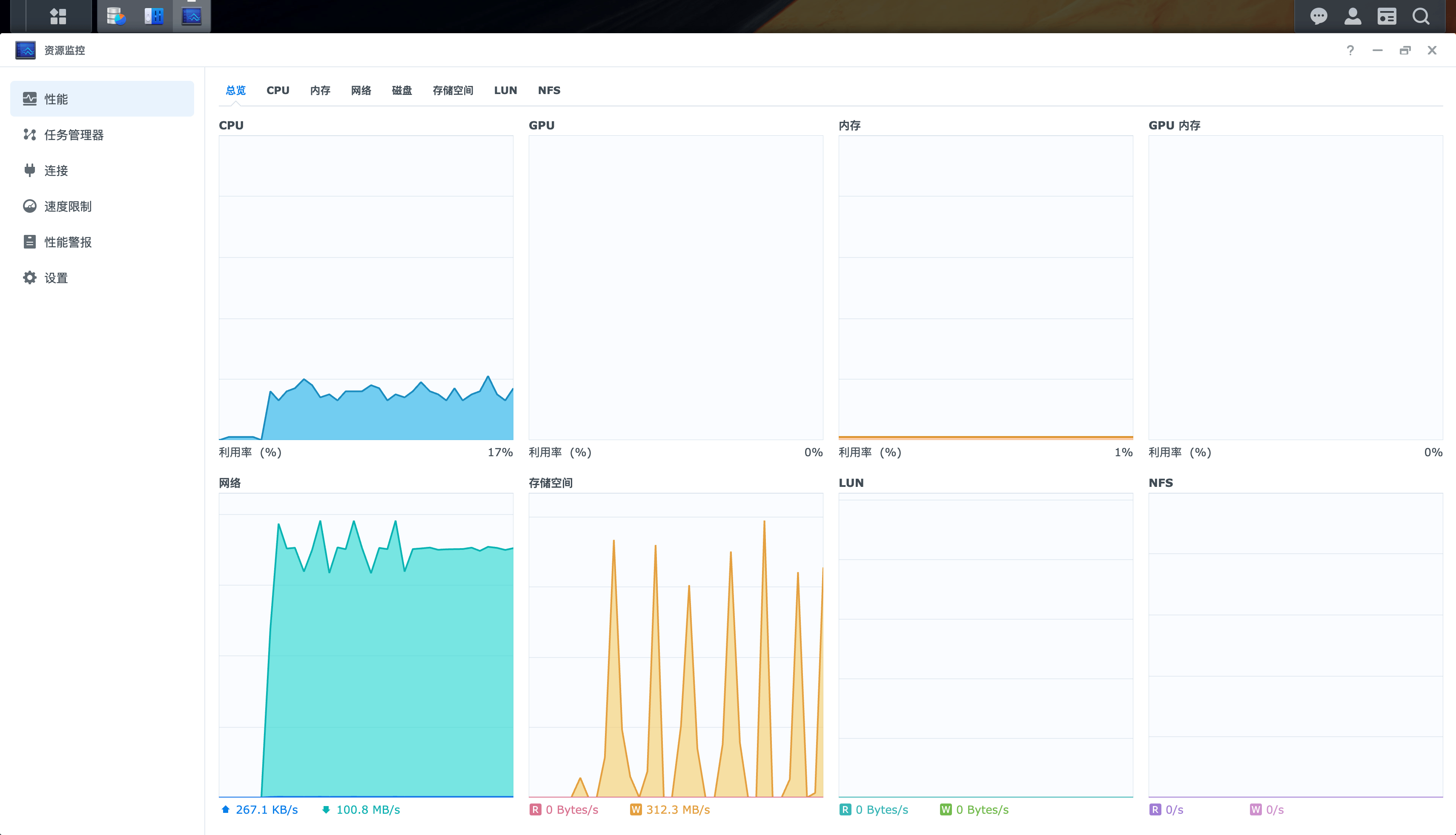
系统整体情况:
磁盘空间占用情况:
实时监控
老系统基本读取分散在多块磁盘
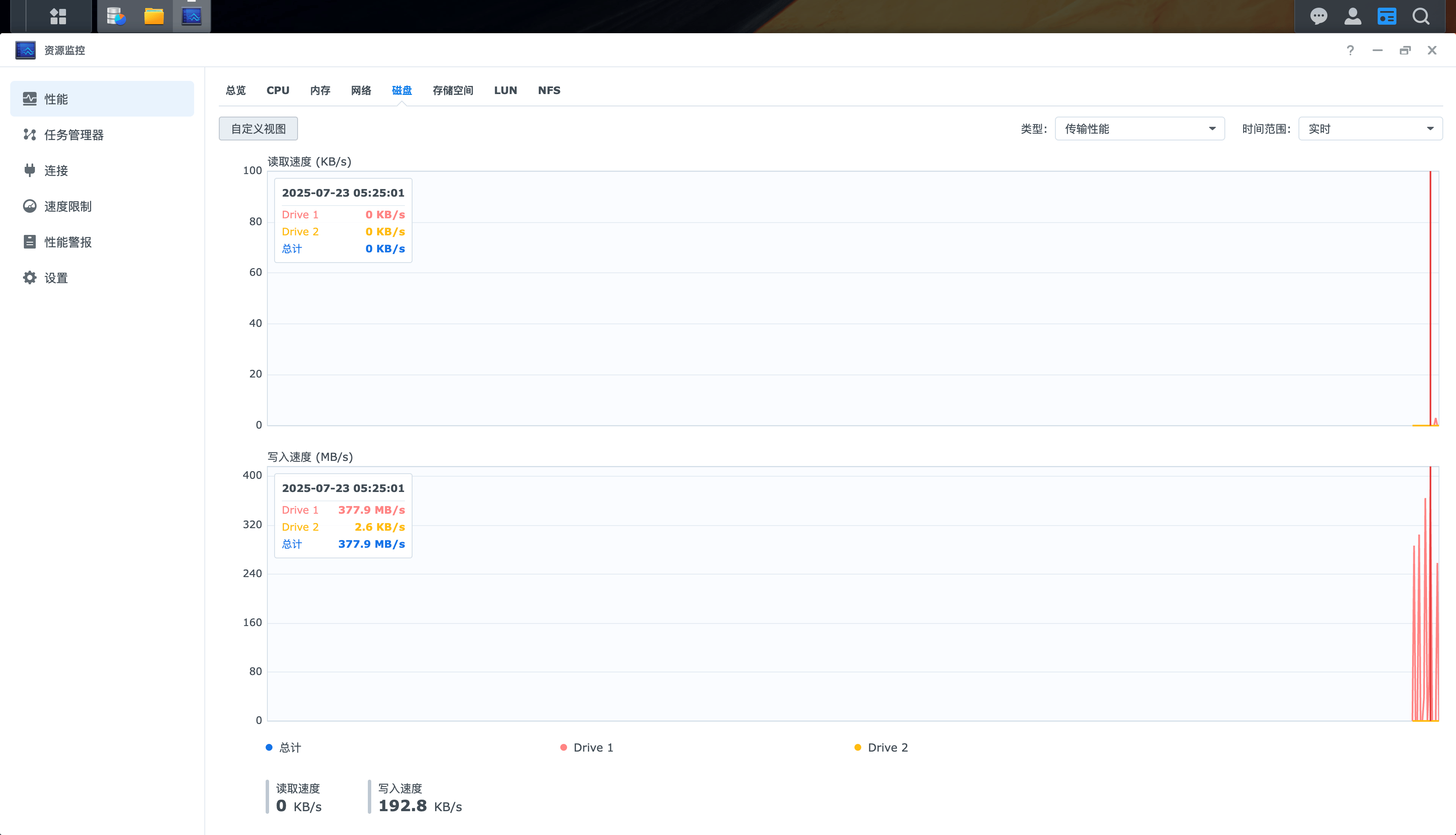
新系统基本往一块磁盘进行写入
从虚拟机层面监控
老设备
磁盘设备读取稳定在100M/s
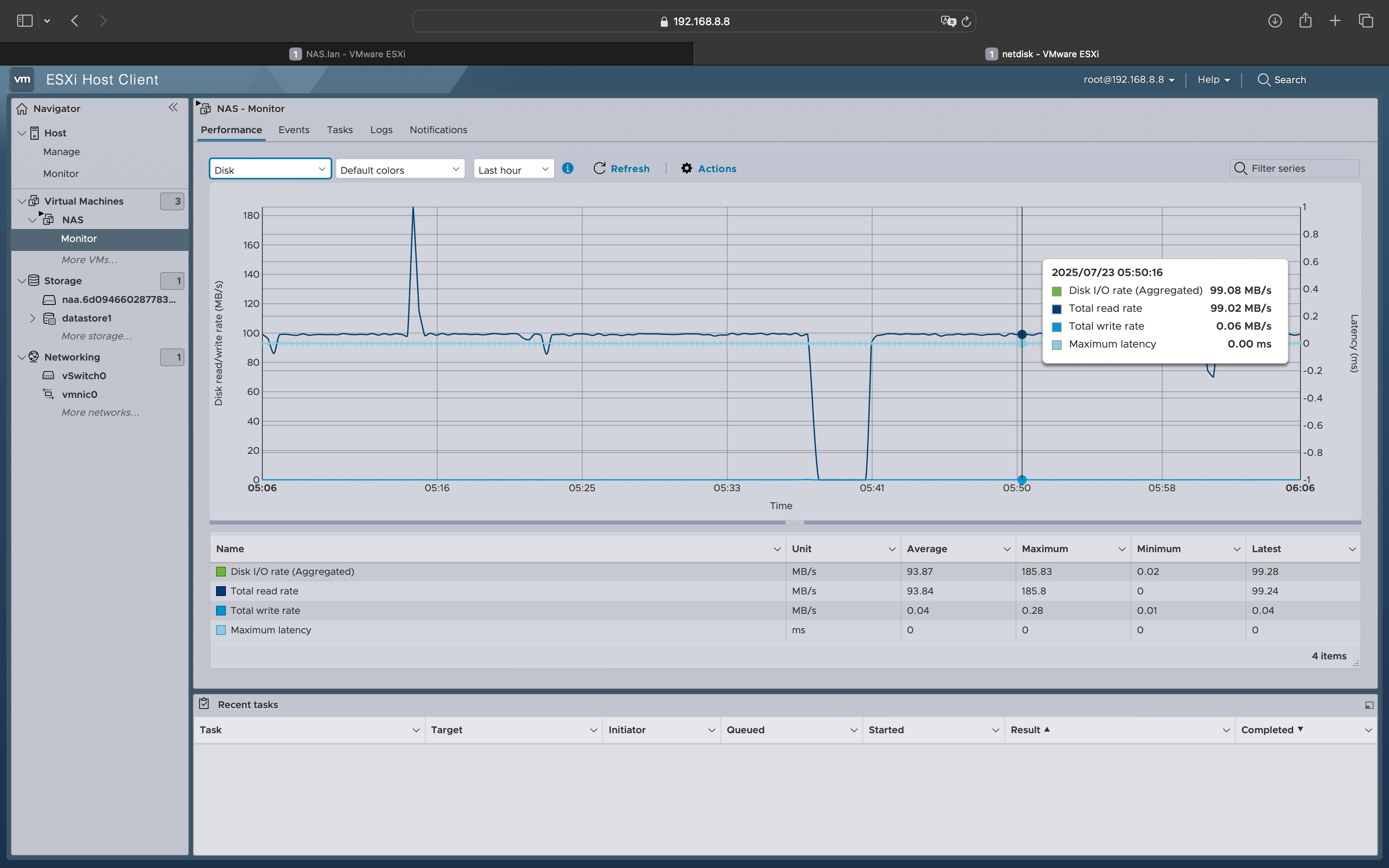
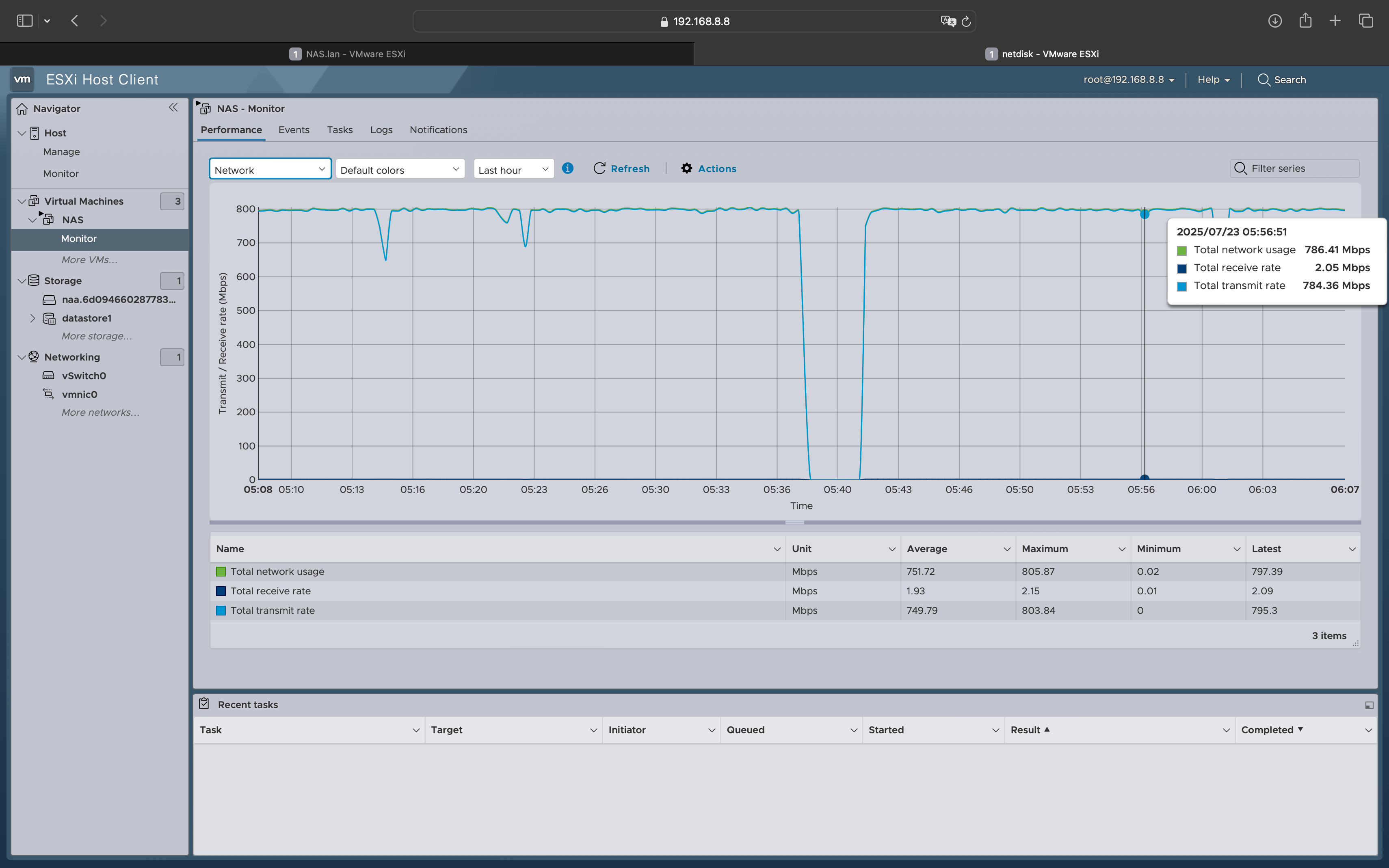
网络开销:800M/s
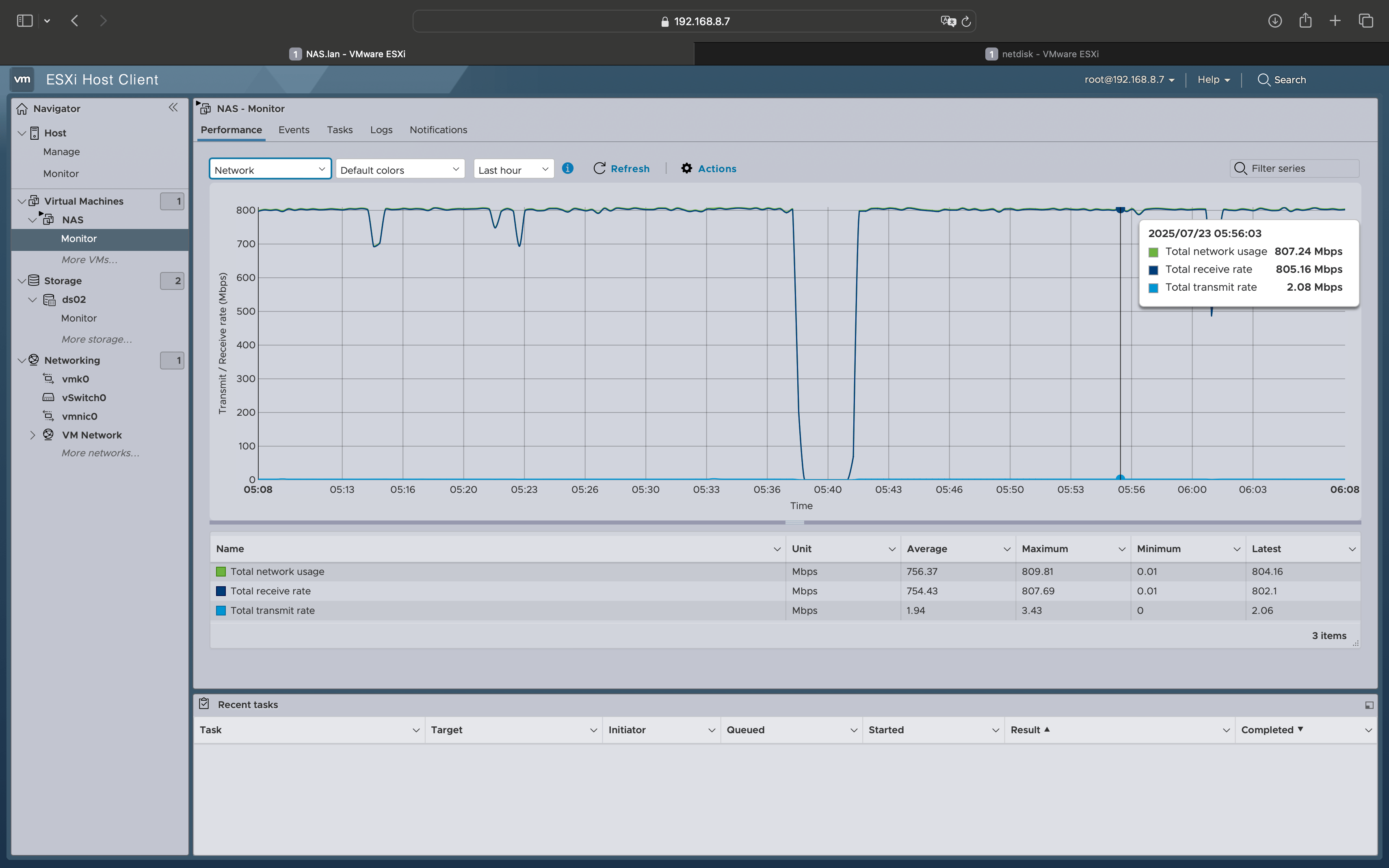
新设备:
网络开销:800M/s
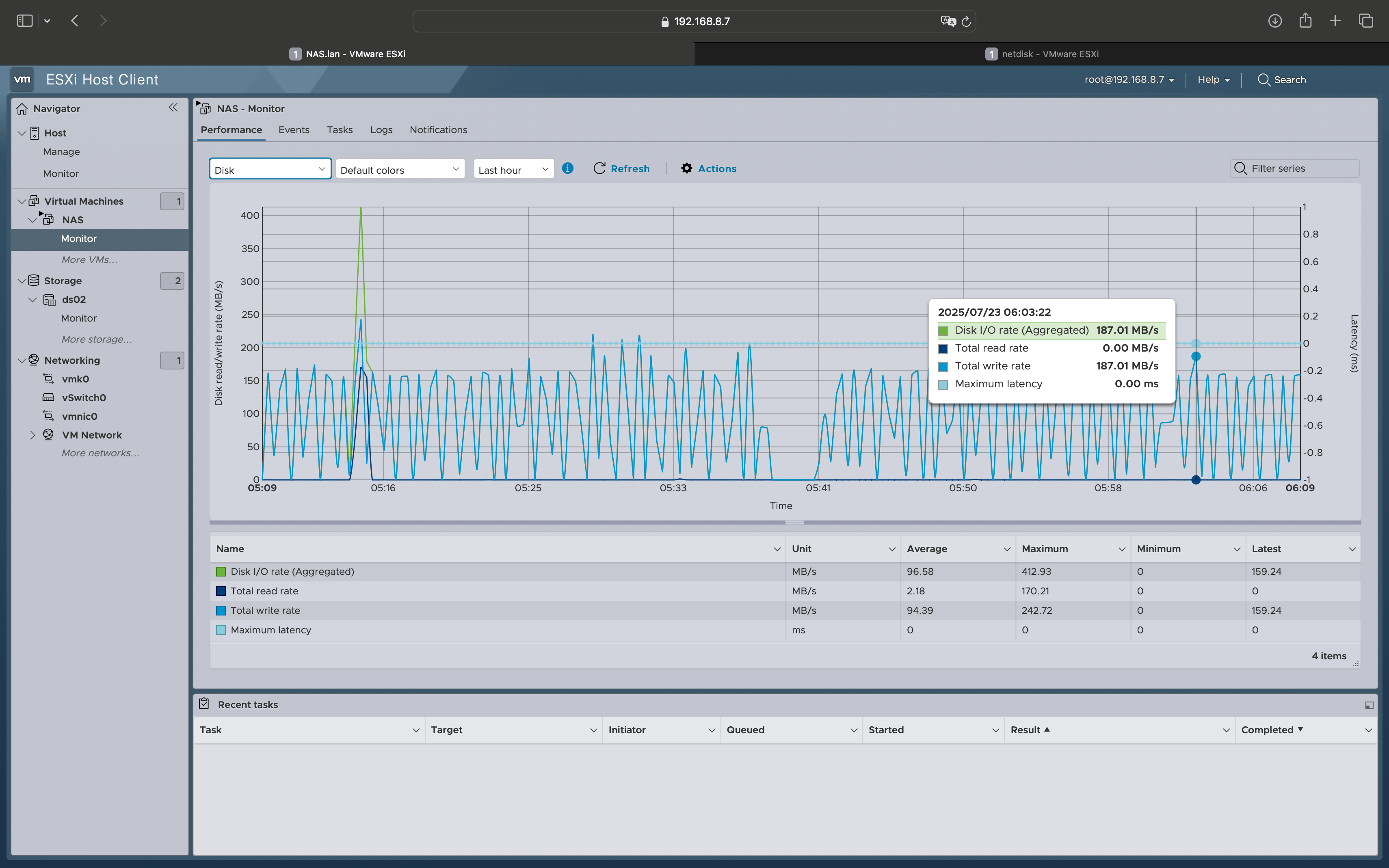
磁盘写数据不太稳定:峰值到了187M/S
逐步恢复
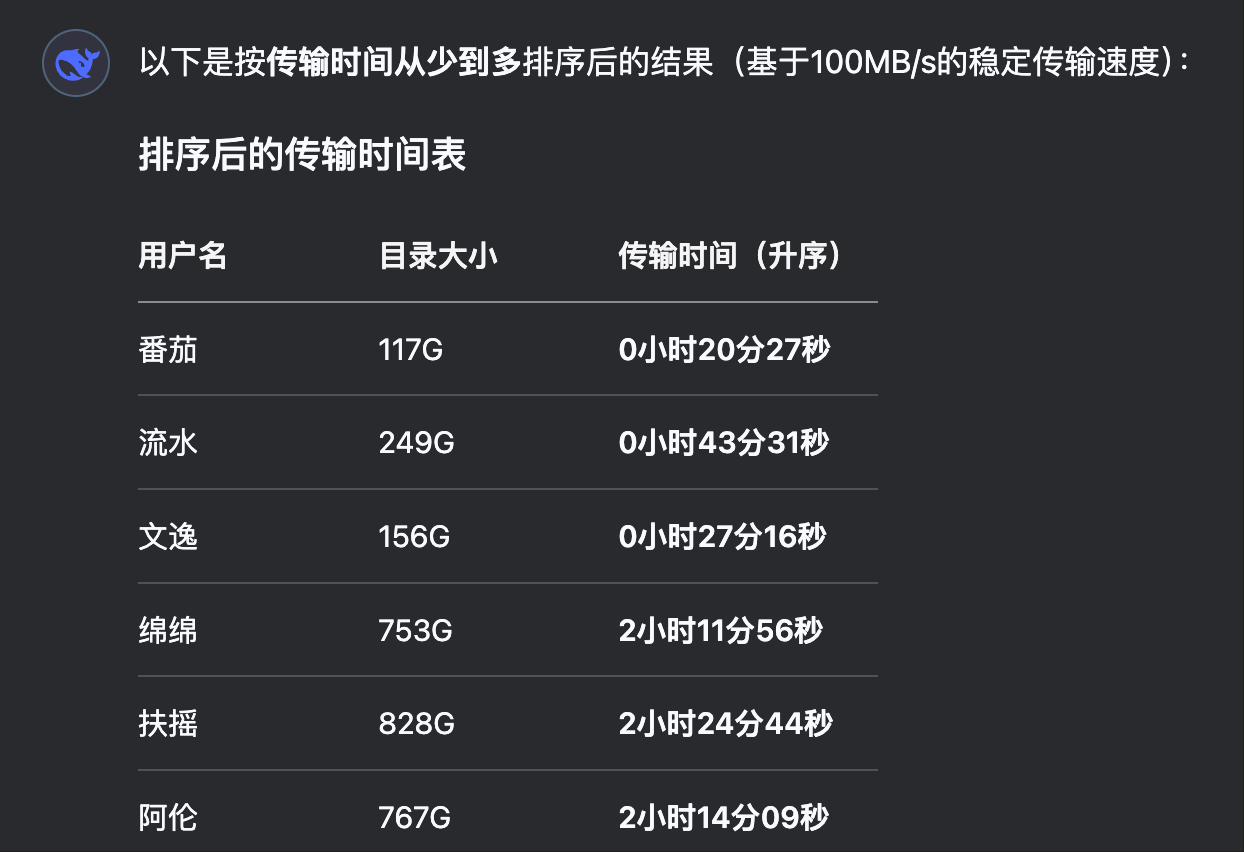
由于数据量非常大,接近 40T ,所以只能选择逐步恢复,这里我们根据用户的紧急程度和占用磁盘大小来安排逐步恢复数据。
不然,突然大量的磁盘读写操作,也会导致新机器扛不住。
后记
数据备份、特别是重要数据的备份,还是很重要的。
接下来,等新机器数据恢复完成后,会再搭建一个NAS服务器,组成集群。这样,数据就会更加安全。